May 27, 2026
How AI Coding Agents Like Claude Code Prevent Massive Context Windows From Collapsing
By Devflares
Modern AI coding agents feel deceptively intelligent. We ask them to analyze entire repositories, debug architecture problems, and continue long-running sessions as if they possess infinite memory.
But underneath that premium experience sits one of the hardest engineering constraints in modern artificial intelligence systems: the physical and semantic limits of the context window.
"As AI agents transition from simple assistants to autonomous operating environments, managing memory becomes a critical engineering challenge that dictates system success.
Why this matters now: In a fast-paced development landscape, companies that build and deploy AI systems must look beyond model parameters. Smarter context management leads to faster execution, reduced token costs, and higher reliability, while unmanaged context leads to hallucinations and runaway cloud bills.
Original source note: This article is inspired by Anthropic’s official Claude Code documentation on the context window, including how Claude Code loads project memory, handles subagents, performs compaction, and manages token usage during long-running development sessions.
The Real Meaning of a Context Window
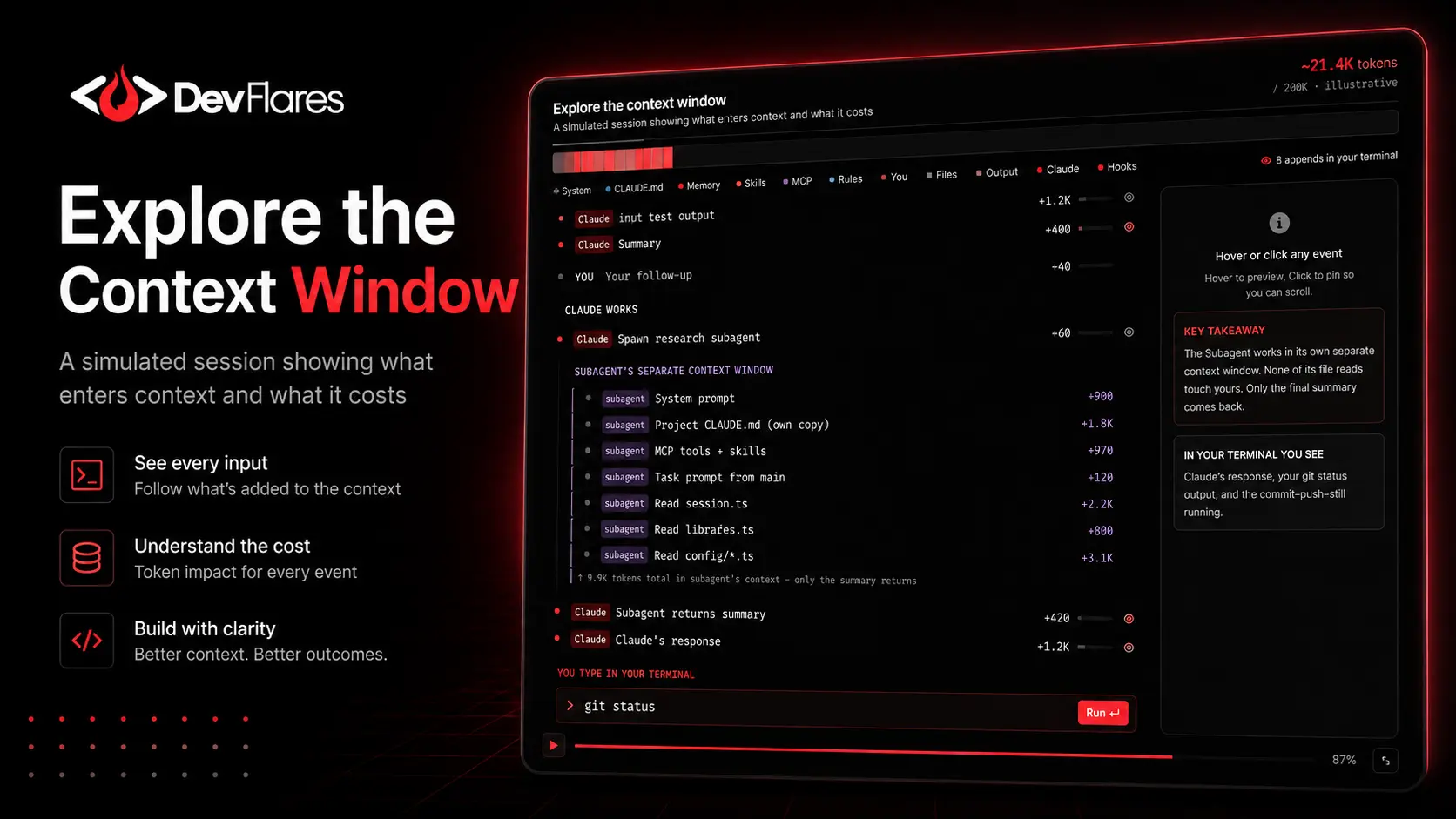
A context window is the active working memory available to an AI model during a session. Everything the model “knows right now” lives inside this window. This includes user prompts, previous conversation history, active source code, terminal tool outputs, safety system instructions, project-level rules, and the generated response itself.
In AI coding environments, this context grows extremely fast. A single enterprise monorepo can contain thousands of files, complex dependency graphs, long build logs, and detailed documentation. Even models supporting 200K, 500K, or 1M+ token windows can run into memory pressure surprisingly quickly, proving that raw size alone is not a complete solution.
The Hidden Context Tax Most Developers Never Notice
One of the biggest misconceptions around long-context AI systems is that developers get access to the full advertised token window. In reality, a meaningful portion of that window may be consumed before the user types their first task-specific prompt.
AI-native systems preload startup context before the first user prompt, including system instructions, project memory files such as CLAUDE.md, auto memory, MCP tool names, skill descriptions, and other session-level configuration. Anthropic’s Claude Code documentation shows that this startup context varies by setup, which means the practical usable window is often smaller than the headline token limit. The real engineering question is not just “How large is the context window?” but “How much of that window is relevant, reusable, and actively helping the task?”

Intelligent Memory Management
How modern AI agents overcome the limitations of finite context windows to maintain high-performance, long-running sessions.
1 Automatic Context Compaction
One of the most important optimizations in modern coding agents is context compaction. Instead of simply deleting older messages when memory fills up, the agent compresses the conversation into smaller semantic summaries.
This process reduces irrelevant tool outputs and compresses older discussions while preserving active tasks, architectural decisions, and repository references. This matches how human memory works: we rarely recall conversations word-for-word, but we retain the core meaning, decisions, and intent. Compaction keeps long-running sessions highly useful.
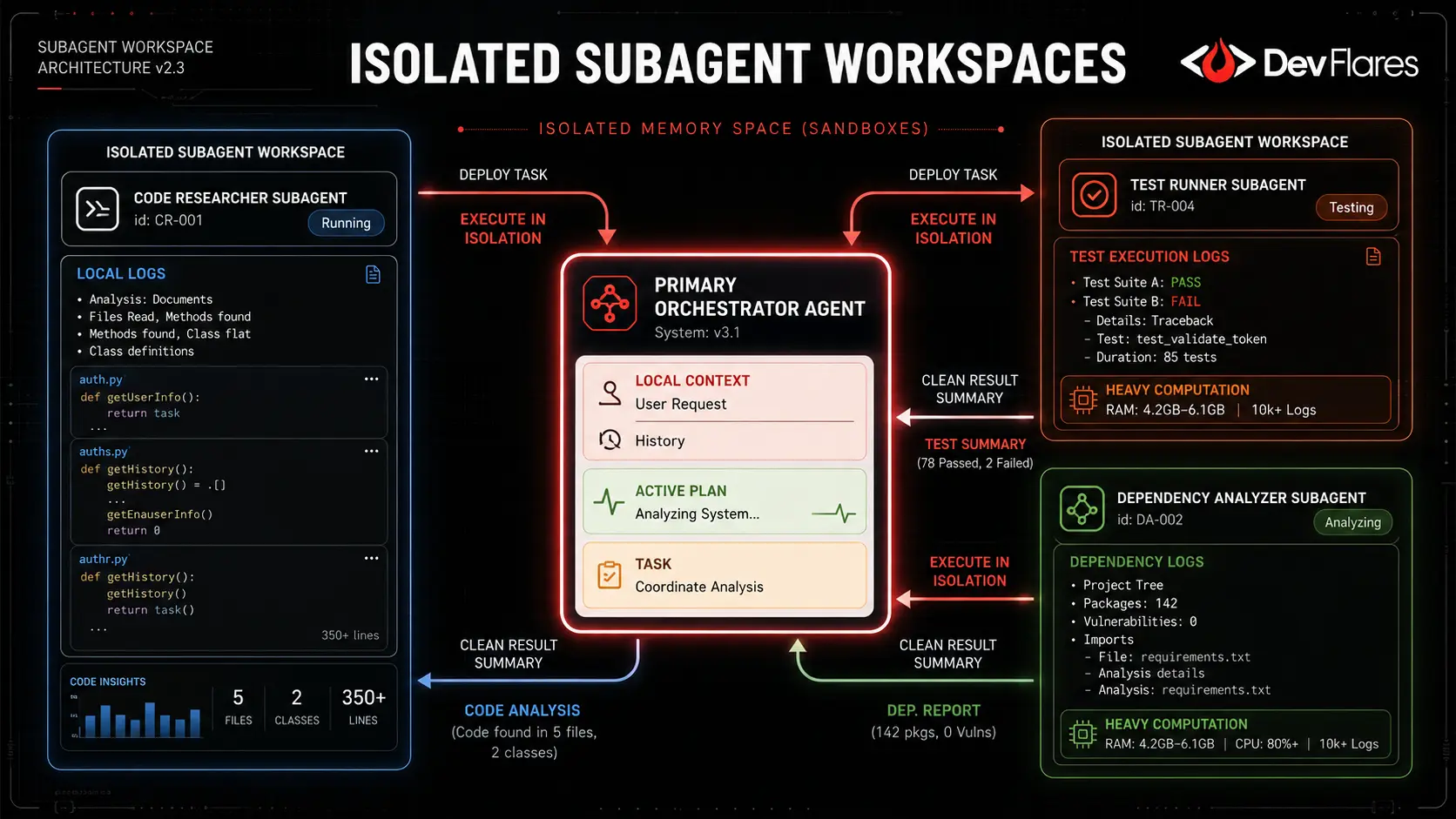
2 Subagents Use Isolated Windows
A brilliant design decision in agentic systems is delegating tasks to subagents operating in separate context windows. Large-scale research operations, such as analyzing a massive dependency graph, do not pollute the primary session memory.
The subagent operates independently to read logs and files, resolving its isolated task before returning only its final conclusions, summaries, and recommended actions back to the main agent. This architecture resembles distributed computing worker processes, preventing token explosion in the primary workspace.
3 Demand-Based Memory Loading
Instead of permanently loading every instruction file into active memory, advanced agents can rely on scoped and project-specific memory. Rules such as directory-specific guidelines or skill definitions become most valuable when they are concise, relevant, and tied to the work being performed.
This approach functions like lazy loading for AI memory, mirroring virtual memory paging and demand-loaded dependencies in traditional operating systems. By keeping irrelevant instructions small or unloaded, the system frees up valuable tokens for actual reasoning and code generation.
4 Skills Need Strict Context Discipline
Persisting reusable workflows or “skills” is a powerful capability, but unrestricted persistence becomes dangerous. AI systems can accumulate prompt bloat, duplicate instructions, and conflicting behaviors that degrade model performance.
To mitigate this risk, modern architectures should treat operational knowledge as a managed, scarce resource rather than infinite storage. Reusable instructions should be concise, scoped, periodically reviewed, and removed when they no longer help the agent perform the task.
5 Layered Memory Architecture
To keep long-running sessions stable, modern systems organize memory into distinct layers. This prevents the agent from forgetting core project rules while still allowing temporary execution details to be summarized or discarded.
- • The Persistent Layer: Contains durable project instructions such as
CLAUDE.md, repository conventions, and team-level rules that should survive across sessions. - • The Temporary Layer: Contains disposable conversational history, intermediate tool outputs, terminal logs, and short-term execution tasks that can be compacted.
Risks & Guardrails
Deploying AI agents with broad system access presents real security and operational risks. Without proper guardrails, agents can run into context collapse, execute destructive commands, or leak proprietary data.
Practical Rollout Plan
Adopting AI coding agents in an enterprise environment should be a phased, de-risked process to ensure developer adoption and maintain code quality.
CLAUDE.md files to align agent behavior with your team’s coding guidelines.Sources & Further Reading
For readers who want to explore the technical details behind this article, these official Claude Code resources provide useful background on context windows, memory, subagents, prompt caching, and cost optimization.
- Claude Code: Explore the context window — Anthropic’s interactive breakdown of what loads into Claude Code context, when rules fire, how subagents isolate work, and what happens after compaction.
- Claude Code: How Claude remembers your project — Explains
CLAUDE.md, auto memory, scoped project rules, and how project instructions are loaded into context. - Claude Code: Create custom subagents — Covers isolated task-specific agents that can investigate, search, and summarize without bloating the main working context.
- Claude Code: Best practices — Practical guidance on managing context, using subagents, writing effective project instructions, and scaling agentic workflows.
- Claude Code: Prompt caching — Explains how repeated context can be reused to improve speed and reduce cost during ongoing sessions.
- Claude Code: Manage costs effectively — Details how token costs scale with context size and how compaction, caching, and usage controls help manage spend.
Where DevFlares Helps
DevFlares specializes in engineering secure, reliable, and high-performance AI enablements for growing enterprises. We architect custom agentic workflows, design custom RAG systems, and build robust, secure backend systems on NestJS and Node.js that leverage the power of modern LLMs safely.
Ready to build highly optimized AI systems and custom software for your operations? Let’s connect to design a tailored solution together.